Scenario
I recently had a situation whereby an NSX-v DLR Control VM had been unintentionally removed from vSphere Inventory, this caused a lot more grief than you would expect.
This DLR CVM was performing L2 bridging for some production workloads that were being migrated off VLAN-backed segments into logical switches. As a result, it was critical that the CVM be powered on and connectivity be restored as soon as possible. This DLR CVM was deliberately deployed as non-HA due to some issues previously faced with L2 bridging/HA split brain/STP loops/shut ports, another post on that some time.
I attempted to redeploy the DLR CVM after being informed of the outage, only to find out that this would not be straight forward. NSX was referencing a non-existent/stale Edge VM that was completely gone and unable to be restored.
This was a NSX 6.4.3 environment. These steps are applicable to both Edge Services Gateway VMs as well as DLR Control VMs.
The steps that created this scenario were as follows:
- DLR CVM was powered off and removed from inventory unintentionally.
- DLR CVM was found on the relevant datastore, reregistered on another host, powered back on, connectivity restored.
- Later that day, the DLR CVM was shutdown and destroyed with no warning whatsoever.
- This was observed by a colleague after the fact while analysing vCenter/NSX Manager logs. DO NOT attempt to reregister the Edge VM if it has been removed from inventory.
- I then attempted to redeploy the CVM via the Networking & Security interface in the vSphere Web Client, this did not work.
- I also tried using the NSX Manager REST API to delete the CVM so that I could deploy a new one, this did not work.
- Following the above failed attempt, I tried to redeploy using the NSX-v Manager REST API, this did not work.
- Tried adding new appliance VM so that it would deploy and then remove the reference to the old/non-existent one, this did not work.
- Although this didn’t error, it did display odd behaviour whereby the new Edge VM showed up as “Undeployed” but disappeared immediately after a UI refresh.
At this point I raised a severity 1 ticket with VMware support who were able to help me resolve this issue, and I hope the following details are useful to anyone else that faces this same issue.
Relevant Information
Things to note:
- My DLR CVM had an ID of edge-4
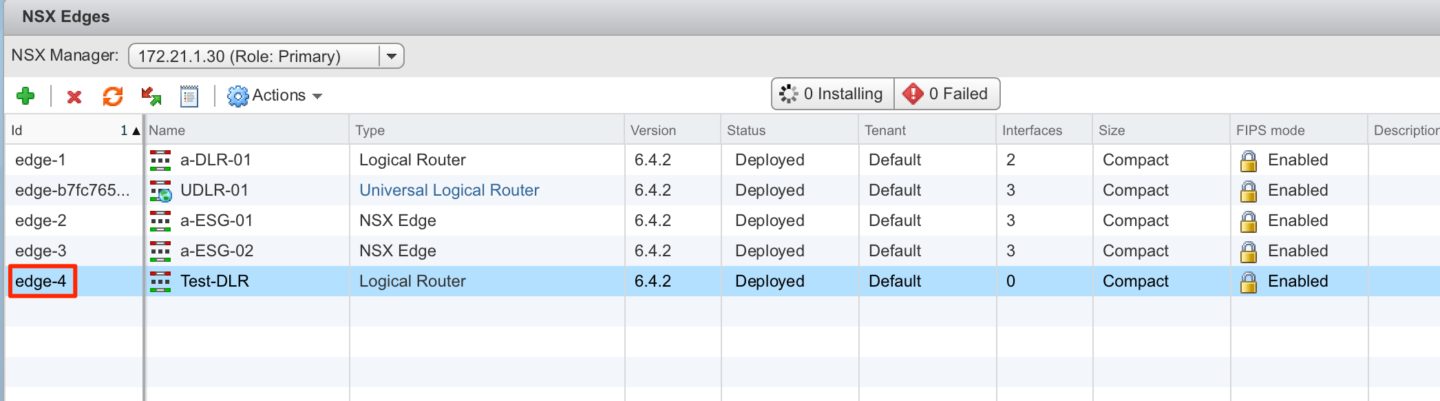
- My DLR CVM was referencing a VM with an ID of vm-421 (see below)
Log Snippets
These log snippets have been taken from my lab where I reproduced the same issue.
Verify the broken state
Open a console to the relevant NSX-v Manager (preferably via SSH) and go into engineering mode with these steps.
Open the postgres database console:
/opt/vmware/vpostgres/current/bin/psql -U secureall
Enable extended output mode (much easier to read):
\x
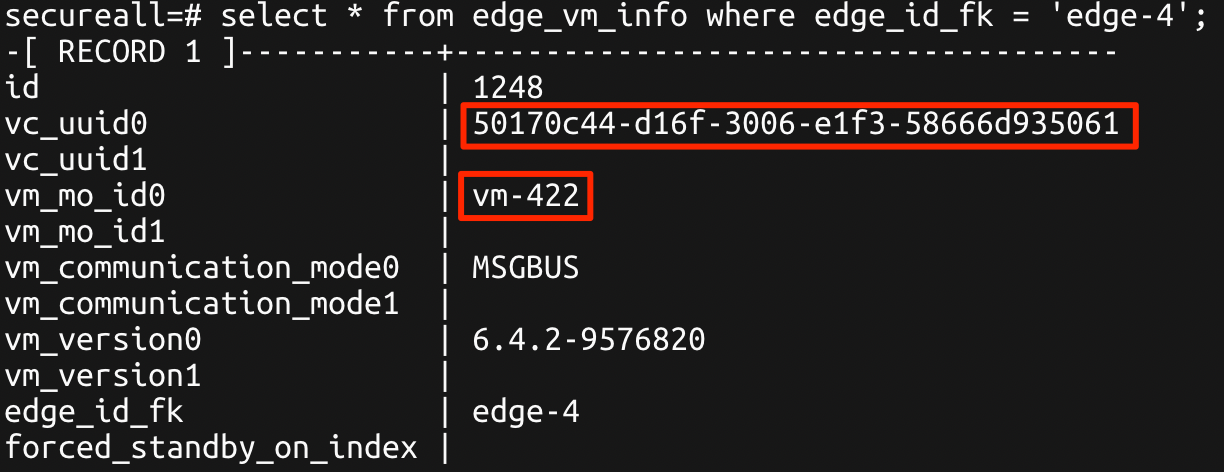
Run the following command (substituting your relevant edge-id):
SELECT * FROM edge_vm_info WHERE edge_id_fk = '<edge-id>';
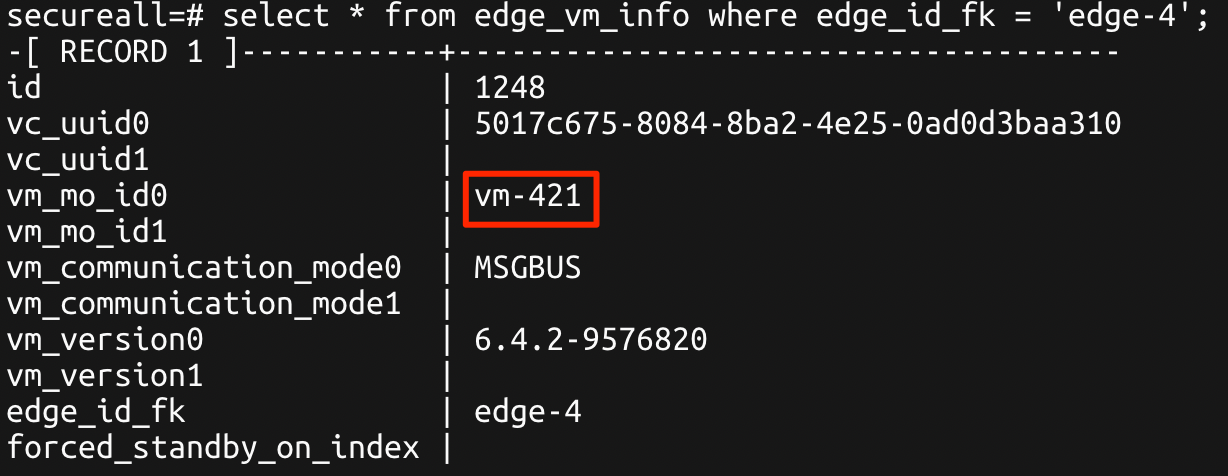
Take note of the vm_mo_id0 value as this is the moref that NSX Manager is using to reference the appropriate DLR CVM in the vSphere Inventory.
At this point you should make certain that the VM in question does not exist in the vSphere inventory. There are a couple of ways of doing this:
- Use the vCenter Managed Object Browser
- https://<vcenter>/mob/?moid=<vm-id>
- This will return a 404 if the VM cannot be found
- https://<vcenter>/mob/?moid=<vm-id>
- Use PowerCLI to find the VM based on ID
- Get-VM -ID VirtualMachine-<vm-id>
- This should return no VMs if the VM cannot be found
- Get-VM -ID VirtualMachine-<vm-id>
At this point you have confirmed that we do in fact need to make some modifications to the NSX-v Manager postgres database so that it no longer references the stale Edge VM.
Resolution
In order to resolve this, the following steps need to be followed:
- Ensure you have a current NSX Manager backup.
- Using the same steps above, ensure you have a postgres console open on the NSX-v Manager.
- Run the following postgres query, take note of the values returned under id_to_be_deleted:
-
SELECT t1.id AS "id_to_be_deleted", t1.datastore_moid, t1.host_moid, t1.resource_pool_moid, t1.vm_hostname, t1.vm_name, t2.edge_id_fk FROM edge_vm t1 INNER JOIN edge_service_config t2 ON t1.edge_config_id_fk = t2.id WHERE t2.edge_id_fk = '<edge-id>';
-
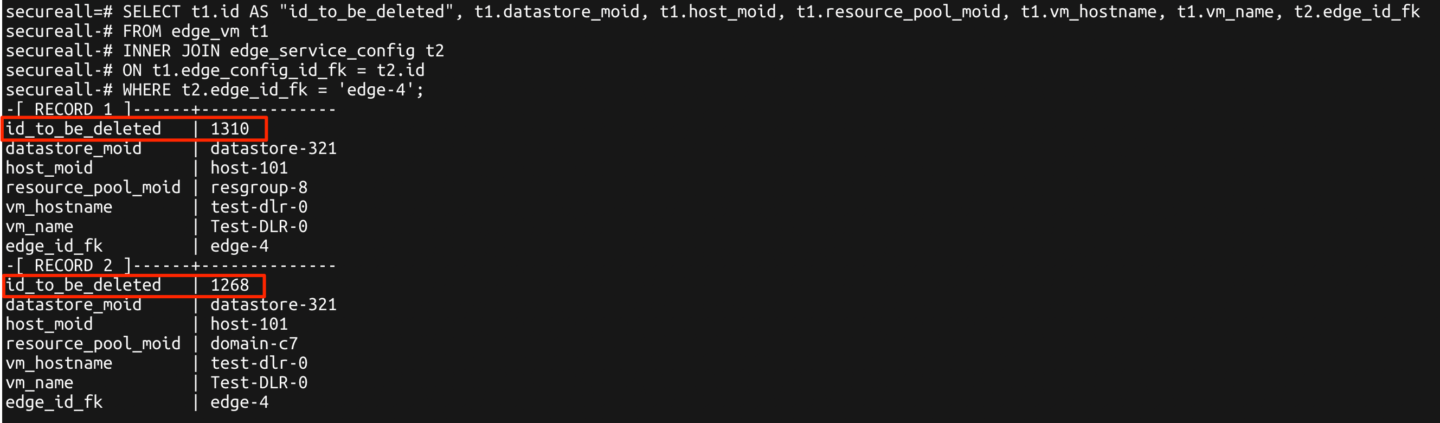
- Run the following select statement(s) and save the output in the event that they need to be referenced after we delete the relevant rows:
-
SELECT * FROM edge_vm WHERE id = <id_to_be_deleted>;
-
- Run the following delete statement(s) to remove the problematic rows so that we can redeploy the edge VM:
-
DELETE FROM edge_vm WHERE id = <id_to_be_deleted>;
-

- You will now observe that there are no configured Edge VMs for the relevant Edge, you can now redeploy a new Edge VM as you would do normally.
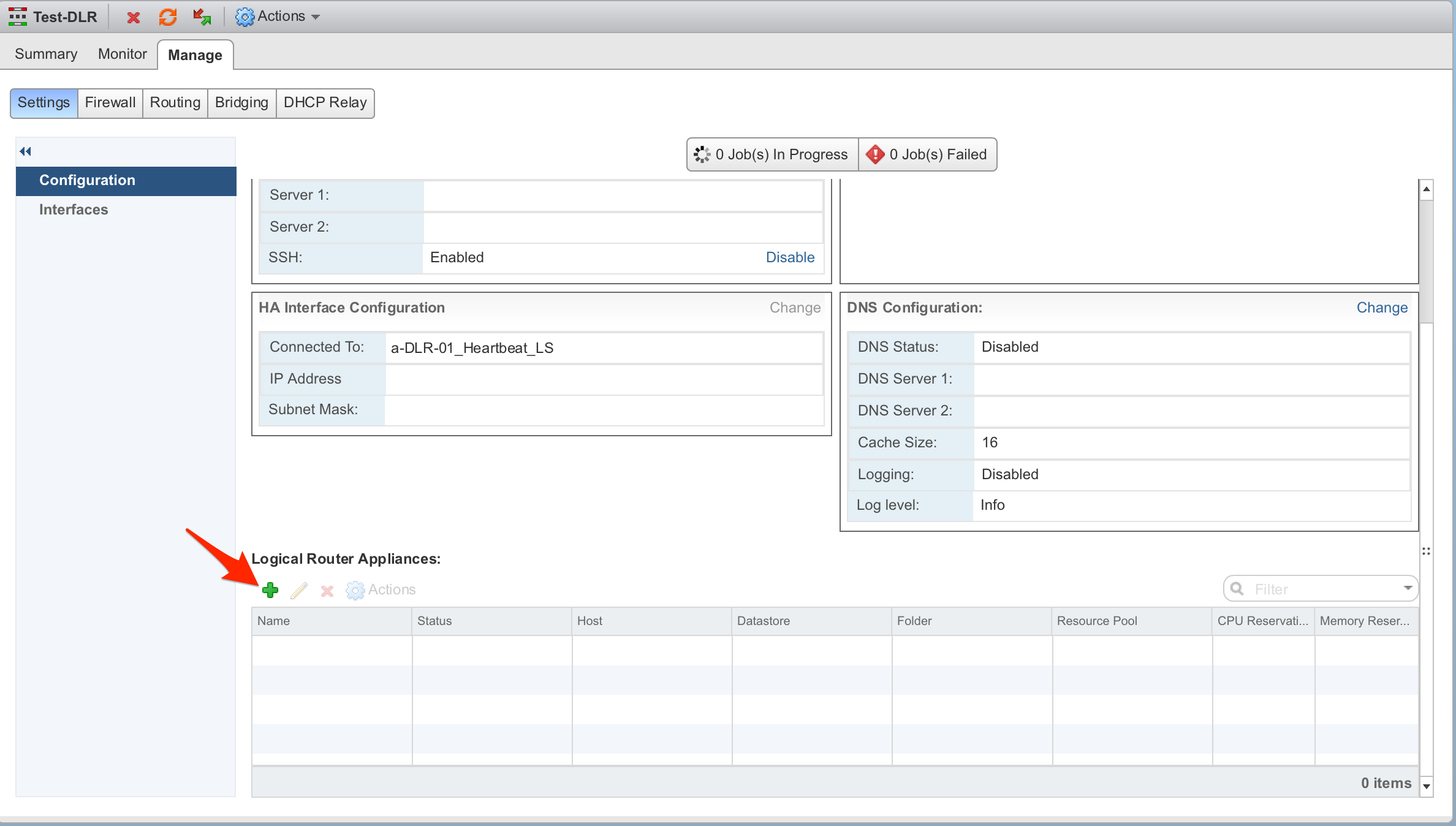
- One last step is required to get the postgres database records updated correctly. The edge_vm table is correct, but there will be stale entries in the edge_vm_info table (referencing stale VC UUID and VC moref values). In order to update this data we need to perform a redeploy operation (could have updated the postgres database manually, but this is a much safer method).
You should now have restored your Edge VM.
Thoughts
Although it is unlikely that an Edge VM would be deleted from disk or removed from inventory in a production/stable environment, these steps will minimise your outage window in the event that it occurs in your environment.
Other options to resolve this were all evaluated for feasibility/effort/reliability but were deemed not the preferred action plan:
- Pulling Edge VM config programatically via API, deleting existing Edge, redeploying new Edge via API
- This may have been problematic due to trying to delete Edge while it was still referencing a non-existent Edge VM. This method could have left the environment in a worse state, stuck trying to delete the Edge.